Generative AI applications
Try Demo
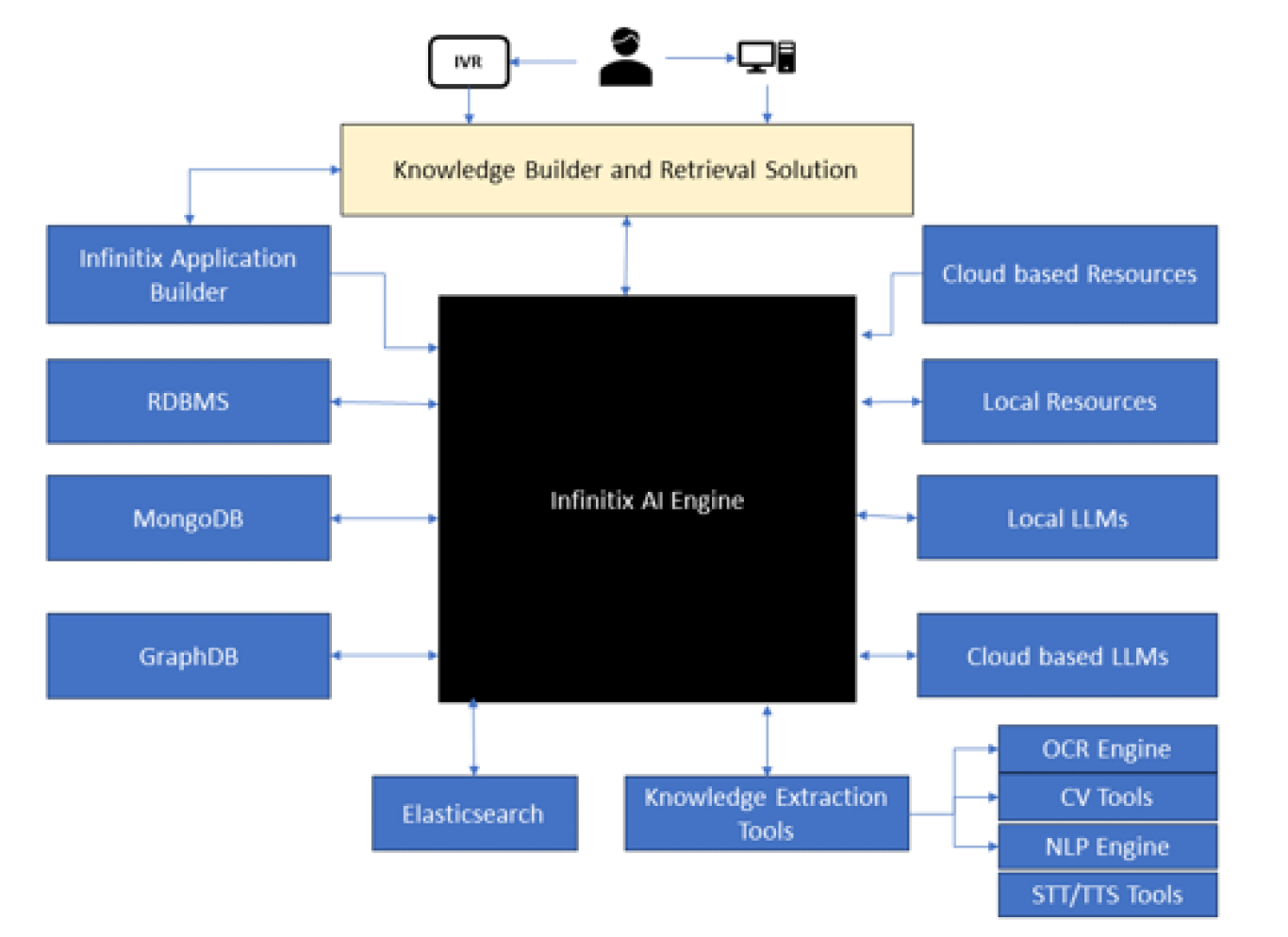
CogniCraft specializes in building large scale analytics solutions using Gen-AI, Machine Learning and Big Data processing capabilities of their goInfinitix platform. Entity de-duplication and Gen-AI based multi-modal Knowledge Management are two areas in which they specialize.
308, NCP Supremus, Wadala E, Mumbai -37 India